|
|
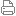
截图来自:https://launchpad.net/ubuntu/+source/linux/3.2.0-39.62
Linux 3.2.0-39.62发布时间:2013年2月27日(我们是3月9日迁入阿里云的)
我们遭遇的“黑色10秒钟”问题详见:云计算之路-阿里云上:超级奇怪的“黑色10秒钟”。
本来准备硬啃内核代码证明是Xen的问题引起的“黑色10秒钟”,现在不用了。这是Linux内核中Xen paravirtualization spinlock实现的一个bug,Linux 3.2.0-39.62已经修复了这个bug。
我们是在一篇一篇阅读这个帖子(Kernel lockup running 3.0.0 and 3.2.0 on multiple EC2 instance types)的回复时找到答案的。
这个帖子中描述的问题现象与我们遇到的惊人的相似(连回复中提到的虚拟机跳时钟的问题我们也遇到过)。帖子是Amazon的工程师在2012年6月11日发现并提交的,通过Amazon工程师与Canonical工程师在回帖中的对话,可以看到老外对待问题的态度。正是他们对问题的执着才最终让Linux的这个bug得到了修复。
有些朋友质疑我们不务正业,浪费时间研究阿里云的东西。
我们的想法是:
首先,阿里云用的是Linux+Xen,这是开源社区的东西,不是阿里云的东西;
其次,我们团队只有一个人投入精力在阿里云的事情上,没有影响正业;
最重要的是,阿里云上有很多很多用户,我们遇到了这样的问题如果不去找出真正的原因,其他用户可能也会经历和我们一样的非常痛苦的折腾。这种折磨人的感觉真是刻骨铭心,我们不想让任何人再经历一次了。这就是我们坚守的最重要的原因!
关于这个bug的关键内容摘录
1. #65楼:From my tests it seems that the problem in the Xen paravirt spinlock implementation is the fact that they re-enable interrupts (xen upcall event channel for that vcpu) during the hypercall to poll for the spinlock irq.
2. 当时对spinlock.c中的xen_spin_lock_slow()部分的代码修改解决了问题:https://launchpadlibrarian.net/124276305/0001-xen-pv-spinlock-Never-enable-interrupts-in-xen_spin_.patch
3. #79楼:After finally having a breakthrough in understanding the source of the lockup and further discussions upstream, the proper turns out to be to change the way waiters are woken when a spinlock gets freed.
4. #86楼:There is currently a Precise kernel in proposed that will contain the first approach on fixing this (which is not to enable interrupts during the hv call). This should get replaced by the upstream fix (which is to wake up all spinners and not only the first found).
bug发生过程分析
来自Patchwork [25/58] xen: Send spinlock IPI to all waiters:
1. CPU n tries to schedule task x away and goes into a slow wait for the runq lock of CPU n-# (must be one with a lower number).
2. CPU n-#, while processing softirqs, tries to balance domains and goes into a slow wait for its own runq lock (for updating some records). Since this is a spin_lock_irqsave in softirq context, interrupts will be re-enabled for the duration of the poll_irq hypercall used by Xen.
3. Before the runq lock of CPU n-# is unlocked, CPU n-1 receives an interrupt (e.g. endio) and when processing the interrupt, tries to wake up task x. But that is in schedule and still on_cpu, so try_to_wake_up goes into a tight loop.
4. The runq lock of CPU n-# gets unlocked, but the message only gets sent to the first waiter, which is CPU n-# and that is busily stuck.
5. CPU n-# never returns from the nested interruption to take and release the lock because the scheduler uses a busy wait. And CPU n never finishes the task migration because the unlock notification only went to CPU n-#.
http://**blogs.com/cmt/archive/2013/06/02/3113762.html |
|






 发表于 2013-6-3 12:34:02
发表于 2013-6-3 12:34:02
 QQ好友和群
QQ好友和群 QQ空间
QQ空间 收藏
收藏